
CDN 是什么?
内容分发网络(Content Delivery Network,简称CDN)是建立并覆盖在承载网之上,由分布在不同区域的边缘节点服务器群组成的分布式网络。CDN应用广泛,支持多种行业、多种场景内容加速,例如:图片小文件、大文件下载、视音频点播、直播流媒体、全站加速、安全加速。
HTTP 报文的构成,以及常见的 HTTP 头部有哪些?
HTTP请求报文包含:
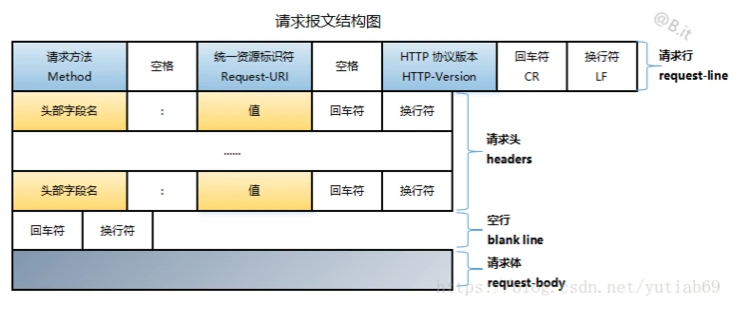
HTTP响应报文包含:
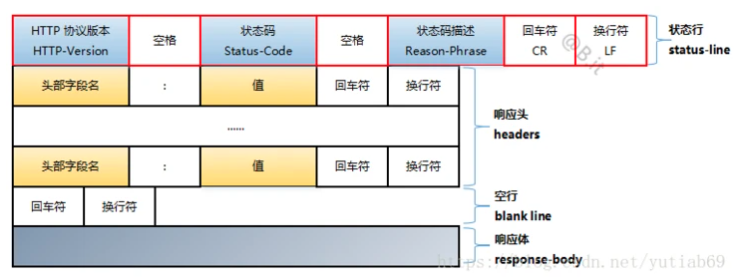
对于请求头/响应头来说,他们又分为通用首部、请求/响应首部、实体首部:
通用首部字段:
| 首部字段名 | 说明 |
|---|---|
| Cache-Control | 控制缓存的行为 |
| Connextion | 逐跳首部、连接的管理 |
| Date | 创建报文的日期时间 |
| Pragma | 报文指令 |
| Transfer-Encoding | 指定报文主体的传输编码方式 |
请求首部字段
| 首部字段名 | 说明 |
|---|---|
| Accept | 用户代理可处理的媒体类型 |
| Accept-Charset | 优先的字符集 |
| Accept-Encoding | 优先的内容编码 |
| Accept-Language | 优先的语言 |
| Host | 指定资源所在服务器 |
| If-Match | 比较实体标记(ETag) |
| If-Modified-Since | 比较资源的更新时间 |
| If-None-Match | 比较实体标记(与If-Match相反) |
| Referer | 对请求中URI的原始获取方 |
| User-Agent | Http客户端程序的信息 |
响应首部字段
| 首部字段名 | 说明 |
|---|---|
| Accept-Range | 是否接受字节范围请求 |
| ETag | 资源的匹配信息 |
| Location | 另客户端重定向至指定URI |
| Server | Http服务器的安装信息 |
| Vary | 代理服务器缓存的管理信息 |
实体首部字段
实体首部字段,就是用来表示实体内容和要求的字段
| 首部字段名 | 说明 |
|---|---|
| Allow | 资源可支持的Http方法 |
| Content-Encoding | 实体主体适用的编码方式 |
| Content-Language | 实体主体的自然语言 |
| Content-Length | 实体主体的大小(字节) |
| Content-Location | 替代对应资源的URI |
| Content-Type | 实体主体的媒体类型 |
| Expires | 实体主体过期的日期时间 |
| Last-Modified | 资源的最后修改日期时间 |
从以上这些之外,还有比如Cookie、Set-Cookie和Content-Disposition等在其他RFC中定义的首部字段也经常被用到。
电脑的ip是如何分配的
用ping指令得到的百度ip能直接访问,但为什么用ping指令得到的知乎ip不能直接访问
为了加快网站的访问速度,当用户访问知乎的域名后跳转到一个代理服务器上,代理服务器根据请求头的 host 再将请求转发到真正的知乎服务器上,再将资源返回给用户。
然而通过 ping 指令 ping zhihu.com 得到的 ip 地址只是一个代理服务器的地址,我们用浏览器直接访问这个地址后,由于缺少了必要的请求头,代理服务器将无法得知需要将该请求转发到何处,同时代理服务器本身是不允许用户直接访问的,因此浏览器将会根据代理服务器的设置而显示不同的错误页面(如 400 Bad Request)。
http 1.1 与 1.0 的区别 2.0 新增了什么
1.0 和 1.1 的区别:
缓存处理,在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
带宽优化及网络连接的使用,HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
错误通知的管理,在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
Host头处理,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。
长连接,HTTP 1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启Connection: keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。
1.1 和 2.0 的区别:
新的二进制格式(Binary Format),HTTP1.x的解析是基于文本。基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合。基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮。
多路复用(MultiPlexing),即连接共享,即每一个request都是是用作连接共享机制的。一个request对应一个id,这样一个连接上可以有多个request,每个连接的request可以随机的混杂在一起,接收方可以根据request的 id将request再归属到各自不同的服务端请求里面。
header压缩,如上文中所言,对前面提到过HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
服务端推送(server push),同SPDY一样,HTTP2.0也具有server push功能。